Exercises
Deadline
This lab will be cloned from your team repo on November 6th at 1pm EST. It should be submitted in a folder called lab8.
Don’t forget to do lab9’s individual portion, which will be due at the same time.
👥 Team
Introduction
Purpose: Use YOLO as a front end object detector to solve a back end estimation problem with GTSAM. Practice developing with ROS2 with less “training wheels”.
Recall, YOLO is a Convolutional Neural Network based on the paper “You Only Look Once: Unified, Real-Time Object Detection”.
In the previous part we setup and used YOLO to detect objects in various images. This time we will use YOLO as a front end to detect an object of interest across multiple frames of a video, and solve for the object’s position with GTSAM by building a factor graph of camera poses with object detections.
The RGB-D TUM dataset is a popular video benchmarking dataset (with ground truth) for various robotic vision applications. We specifically will be using the freiburg3_teddy sequence. This dataset is great, but it was collected in the early 2010s so a few things are outdated (i.e., their video previews use Flash and the data is in ROS1). Luckily, we updated the data for you! Checkout a video preview of freiburg3_teddy here. Our goal will be to determine the position of the Teddy Bear!
Although we still provide starter code for this deliverable, you will be given a lot more freedom implementing this deliverable. This is to better simulate how one might use ROS2 in their research (i.e., with less “training wheels”).
Installation & Setup
This lab assumes you already have your VNAV workspace setup, with ROS2, OpenCV, and GTSAM installed from the earlier labs.
Downloading the dataset as a ROS2 bag
- If you don’t already have one, create a data folder within your VNAV workspace:
mkdir -p ~/vnav/data - Download the
freiburg3_teddysequence as a ROS2 bag here. Place it in~/vnav/data. - Uncompress the data with the following command:
tar xzvf lab8_data.tar.gzYou should now have a folder called
rgbd_dataset_freiburg3_teddywith the following files:~/vnav/data/rgbd_dataset_freiburg3_teddy ├── metadata.yaml └── rgbd_dataset_freiburg3_teddy.db3 - Try running the bag with:
ros2 bag play -l ~/vnav/data/rgbd_dataset_freiburg3_teddyand viewing the image data in either
rvizorrqt. Note the-largument will infinitely repeat the bag replay.
Setup code
- Update the starter code repo:
cd ~/vnav/starter-code git pull - Copy relevant starter code to your
team-submissionsrepo:cp -r ~/vnav/starter-code/lab8 ~/vnav/team-submissions - Link submission code to your code:
mkdir -p ~/vnav/ws/lab8/src cd ~/vnav/ws/lab8/src ln -s ../../../team-submissions/lab8 lab_8 - Clone and setup the Ultralytics ROS2 package:
cd ~/vnav/ws/lab8/src GIT_LFS_SKIP_SMUDGE=1 git clone -b humble-devel https://github.com/Alpaca-zip/ultralytics_ros.git rosdep install -r -y -i --from-paths . python3 -m pip install -r ultralytics_ros/requirements.txt - Build the starter code:
cd ~/vnav/ws/lab8 colcon build - Confirm your
~/.bashrcnow contains the following line to source lab8:source ~/vnav/ws/lab8/install/setup.bash - Re-source your
~/.bashrcto ensure lab8 is sourced in your current session:source ~/.bashrc
Running the starter code
- To test our code, we want to play the ROS2 bag and launch YOLO to process frames:
# terminal 1 ros2 bag play -l ~/vnav/data/rgbd_dataset_freiburg3_teddy # terminal 2 ros2 launch ultralytics_ros tracker.launch.xml debug:=true input_topic:=/camera/rgb/image_colorNote that
input_topic:=/camera/rgb/image_coloris telling YOLO to process data on that bag topic. By default, YOLO will send processed frames to the/yolo_imagetopic. - Open up
rvizorrqtto confirm YOLO is running. Confirm you can see something like this: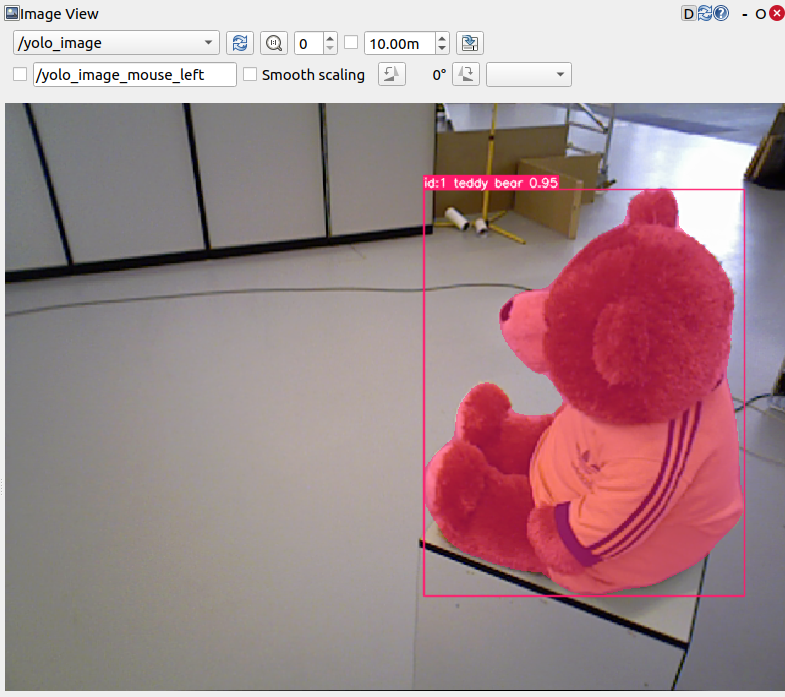 Note: Depending on your computer hardware, YOLO may not run at the same framerate as the original video.
Note: Depending on your computer hardware, YOLO may not run at the same framerate as the original video. - Run the starter C++ code with:
# terminal 3 ros2 run lab_8 deliverable_1The starter code should show you how to get camera pose information from
/tfand pixel information about YOLO’s “Teddy Bear” detections. This will be needed for your implmentation!
📨 Deliverable 1 - Object Localization [45 pts]
Our goal for this exercise is to localize the teddy bear that is at the center of the scene in the freiburg3_teddy dataset. To do so, we will use YOLO detections to know where the teddy bear is. With the bounding box of the teddy bear, we can calculate a crude approximation of the bear’s 3D position by using the center pixel of the bounding box. If we accumulate enough 2D measurements, we can formulate a least-squares problem in GTSAM to triangulate the 3D position of the teddy bear.
For that, we will need to perform the following steps:
- Examine the C++ starter code to understand how we are (i) getting the ground-truth transformation of the camera with respect to the world from the
tftopic and (ii) getting the center of the Teddy Bear bounding box from YOLO. - Formulate a GTSAM problem where we are trying to estimate the 3D position of the center pixel in the bounding box. You will need to use multiple
GenericProjectionFactorsin order to fully constrain the 3D position of the teddy bear and estimate the 3D position of the teddy bear. (Recall the GTSAM exercise where you performed a toy-example of Bundle Adjustment problem and use the same factors to build the problem.) Note that now, the poses of the camera are given to you as ground-truth information, so you might want to this as priors instead of as odometry. Tip: If you need it, the bag file has camera calibration info in thecamera_infotopics. - Solve the problem in GTSAM. (Consider repurposing code from
lab_7!) - In
rviz, plot the (i) estimated 3D position of the teddy bear, (ii) the trajectory of the camera, and (iii) which frames got a good detection of the teddy bear. For instance, yourrvizshould look something like this:

where the green line is (i), purple sphere is (ii), and the red arrows are (iii).
- (Optional) Extra Credit (10 pts) Calculate the covariance of the teddy bear estimate, place it in a
geometry_msgs::PoseWithCovariancemessage, and plot it inrvizusing the size of the sphere to represent the covariance.
What to submit
To evaluate this deliverable, we will examine your implementation, but will not focus on the end result (although it will count). Instead we ask you add a PDF to your team submission repo called lab8-team-writeup.pdf with the following information:
- A small summary of your design choices and considerations taken in order to solve this problem.
- Your “best” estimate of the position of the teddy bear as
geometry_msgs::PointStampedmessage. - A screenshot of
rvizshowing the plotted information (as explained above). - (Optional) If you did the extra credit covariance calculation and plotting above, include an additional screenshot and the “best” estimate of covariance as a
geometry_msgs::PoseWithCovariancemessage.
All together this writeup should be at least 250 words.